Auto_select_gpus always choose gpus [0,1] when devices=2, strategy = dp, accelarator = 'auto' #13012
Description
🐛 Bug
I have tried to use auto_select_gpus in the server to train multiple models concurrently. The first model already occupied 13GB VRAM and 6GB VRAM in GPUs [0,1] respectively. However, the expected behaviors that select different GPUs didn't happen.
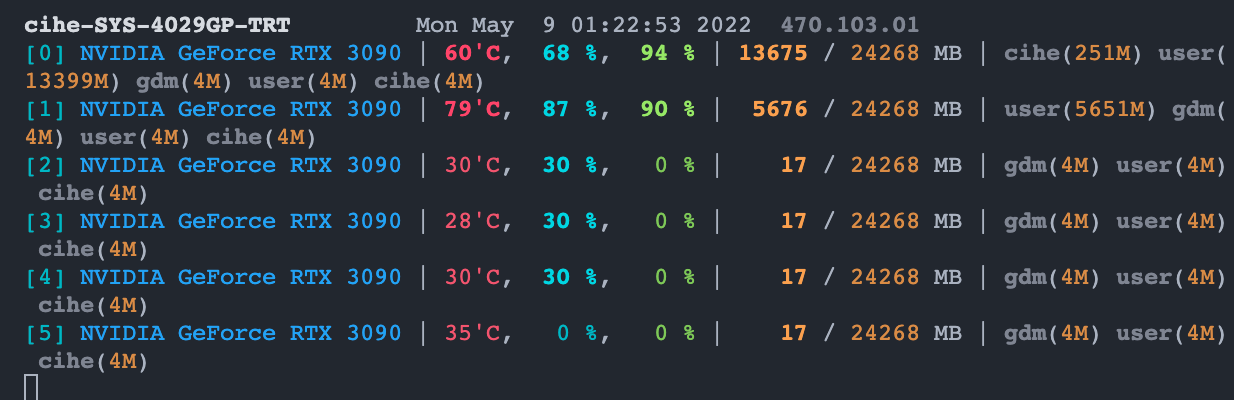
Environment before launching BoringModel
To Reproduce
The following BoringModel is used to test the auto_select_gpus. Launch the following codes twice in separate terminals. When the second model is launched, we may observe that the GPUs [0,1] is still being selected.
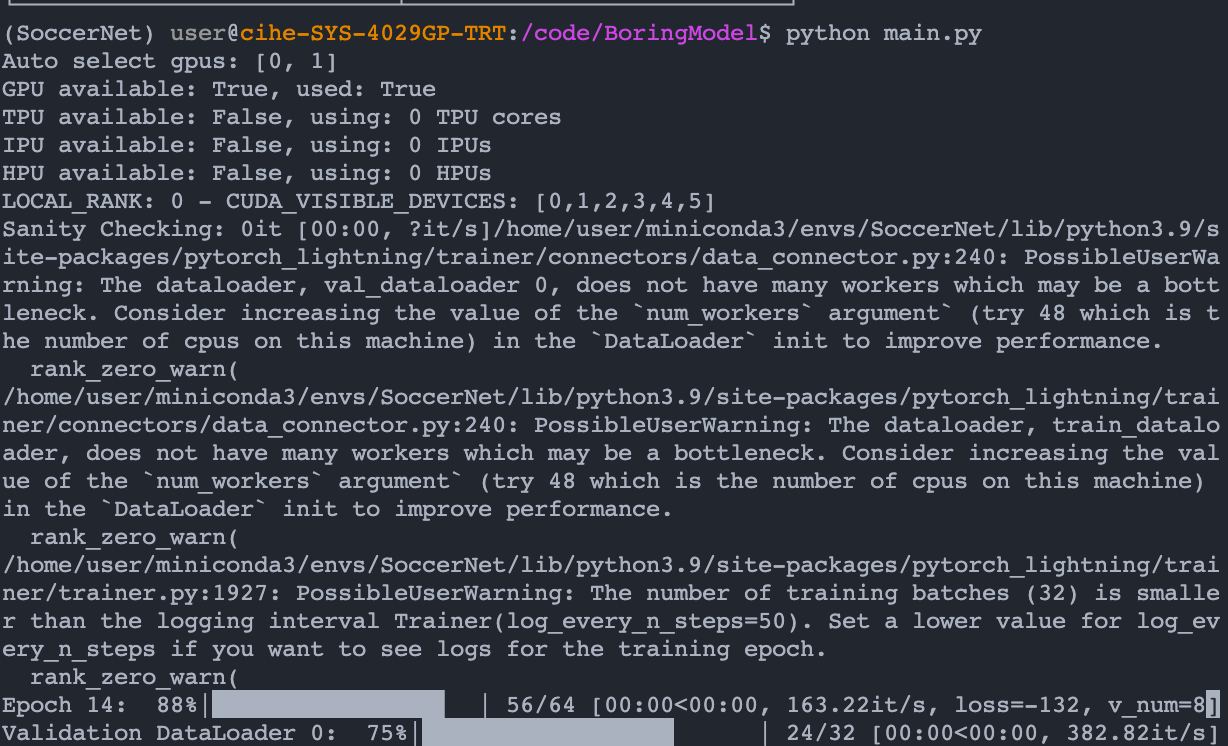
The first line of output indicate the GPUs [0,1] is still being selected.
import os
import torch
from torch.utils.data import DataLoader, Dataset
from pytorch_lightning import LightningModule, Trainer
class RandomDataset(Dataset):
def __init__(self, size, num_samples):
self.len = num_samples
self.data = torch.randn(num_samples, size)
def __getitem__(self, index):
return self.data[index]
def __len__(self):
return self.len
num_samples = 10000
class BoringModel(LightningModule):
def __init__(self):
super().__init__()
self.layer = torch.nn.Linear(32, 2)
def forward(self, x):
return self.layer(x)
def training_step(self, batch, batch_idx):
loss = self(batch).sum()
self.log("train_loss", loss)
return {"loss": loss}
def validation_step(self, batch, batch_idx):
loss = self(batch).sum()
self.log("valid_loss", loss)
def test_step(self, batch, batch_idx):
loss = self(batch).sum()
self.log("test_loss", loss)
def configure_optimizers(self):
return torch.optim.SGD(self.layer.parameters(), lr=0.1)
def run():
train_data = DataLoader(RandomDataset(32, 64), batch_size=2)
val_data = DataLoader(RandomDataset(32, 64), batch_size=2)
test_data = DataLoader(RandomDataset(32, 64), batch_size=2)
model = BoringModel()
trainer = Trainer(
default_root_dir=os.getcwd(),
min_epochs=10000,
max_epochs=20000,
enable_model_summary=False,
devices=2,
auto_select_gpus=True,
strategy='dp',
accelerator='auto'
)
trainer.fit(model, train_dataloaders=train_data, val_dataloaders=val_data)
trainer.test(model, dataloaders=test_data)
run()
The BoringModel used
Expected behavior
The second training code, BoringModel, will select other unused GPUs instead of occupied GPUs [0,1]
Environment
- CUDA:
- GPU:
- NVIDIA GeForce RTX 3090
- NVIDIA GeForce RTX 3090
- NVIDIA GeForce RTX 3090
- NVIDIA GeForce RTX 3090
- NVIDIA GeForce RTX 3090
- NVIDIA GeForce RTX 3090
- available: True
- version: 11.2 - Packages:
- numpy: 1.22.3
- pyTorch_debug: False
- pyTorch_version: 1.10.2
- pytorch-lightning: 1.6.3
- tqdm: 4.62.3 - System:
- OS: Linux
- architecture:
- 64bit
- ELF
- processor: x86_64
- python: 3.9.10
- version: Extend CI #44~20.04.1-Ubuntu SMP Thu Mar 24 16:43:35 UTC 2022
Additional context
cc @tchaton @rohitgr7 @justusschock @kaushikb11 @awaelchli @akihironitta